23. Juni 2010
HTML nachträglich mit Javascript bearbeiten
In Shopsystemen aber auch bei anderen fremdgehosteten Seiten gibt es immer wieder Stellen im HTML Code, welche sich nicht über Templates bearbeiten lassen. Hier kann man oftmals mit JavaScript eingreifen. Dieser Artikel zeigt Möglichkeiten, auch ohne benannte IDs oder Klassen, HTML Code gezielt zu manipulieren.
Vielen ist sicher bekannt, dass man mit der JavaScript Eigenschaft innerHTML Quelltext innerhalb eines Tags auslesen bzw. beschreiben kann. Angesprochen wird das zu bearbeitende Element normalerweise mit document.getElementsById(‚id‘). Im Prinzip eine sehr mächtige Funktion, doch in der Praxis kommt meistens alles anders – man hat keine IDs oder die Abfrage muss inhaltsabhängig sein. In diesem Beispiel geht es darum, alle Tabellenzeilen, welche eine leere Zelle enthalten auszublenden. Wir bedienen uns hierfür der Eigenschaft getElementsByTagName(‚tr‘) , welche alle TRs im Quelltext in einem Array speichert:
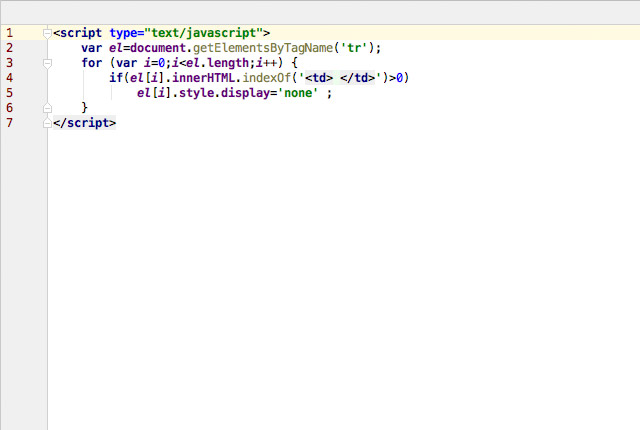
<script type="text/javascript">
var el=document.getElementsByTagName('tr');
for (var i=0;i<el.length;i++) {
if(el[i].innerHTML.indexOf('<td> </td>')>0)
el[i].style.display='none' ;
}
</script>
Erklärung des Quelltextes:
2. Zeile: Die Handles aller TRs werden in das Array el gespeichert. Dies würde auch mit jedem anderen HTML Element funktionieren.
3. Zeile: Das Array wird in einer FOR-Schleife ausgelesen
4. Zeile: Es wird nach einer leeren Zelle <td> </td> gesucht – man könnte auch nach einem beliebigen Wort suchen.
5. Zeile: Bei einem Fund wird die aktuelle Tabellenzeile per display: none ausgeblendet, man könnte hier alternativ auch den Inhalt per innerHTML ändern.
Der Quelltext muss unter dem zu bearbeitenden Quelltext stehen!

In diesem Beispiel sorgt das Skript dafür, dass die nicht gemachten Angaben in einer Adressausgabe komplett ausgeblendet werden.
